
以下、自分が今後メンテナンスする為にも必要なのでメモっておく。
tl;dr
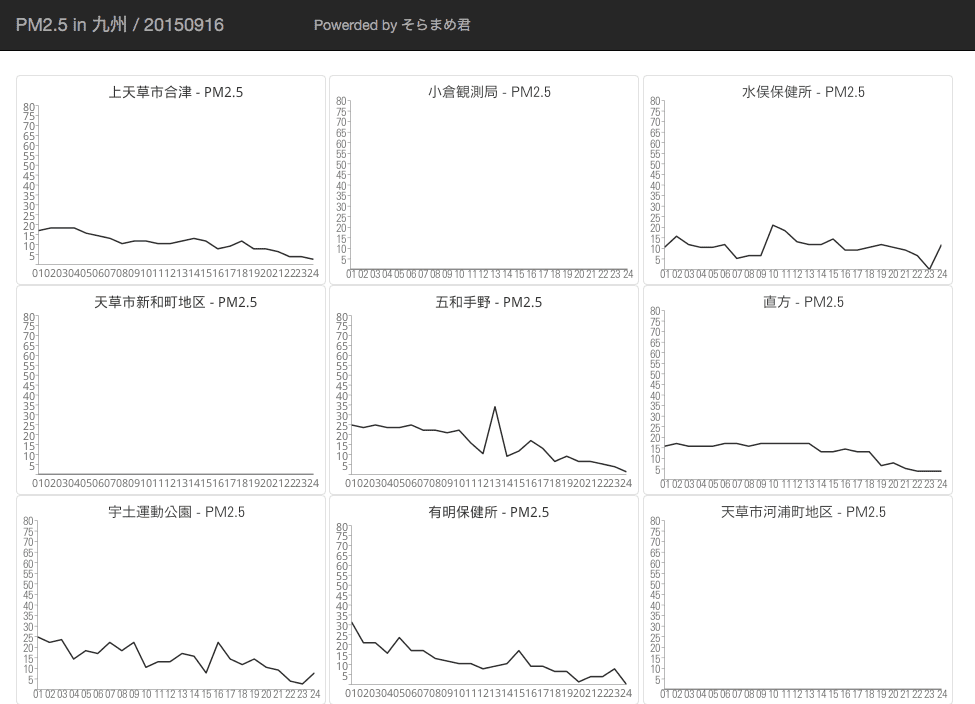
今までの復習のつもりで DynamoDB + Datapipeline + S3 + Google Chart API を少しずつ使ってそらまめ君で提供されている大気中の汚染物質濃度速報データを可視化するサイトを作ってみた。
既に以下のような API やアプリを作成されている方がいらっしゃるのでリアルタイムに情報を取得したい場合にはそちらを利用しましょう。
- (Android)大気汚染物質広域監視システム「そらまめ君」の簡易受信アプリ – OasisHalfmoon
- 環境省大気汚染物質広域監視システム(そらまめ君)のAPIを作ってみた。 – hachiBucchのブログ
自分が作ったのは前日分の PM2.5 濃度の遷移を見れるだけのシンプルなものなので、夏休みの自由研究とかにコピペで使ってもらえると嬉しいなあ…既に夏休みは終わっているけど。(来年の夏休みの時期まで運用されていれば貴重なデータベースになっていることでしょう…)
memo とかウンチクとか
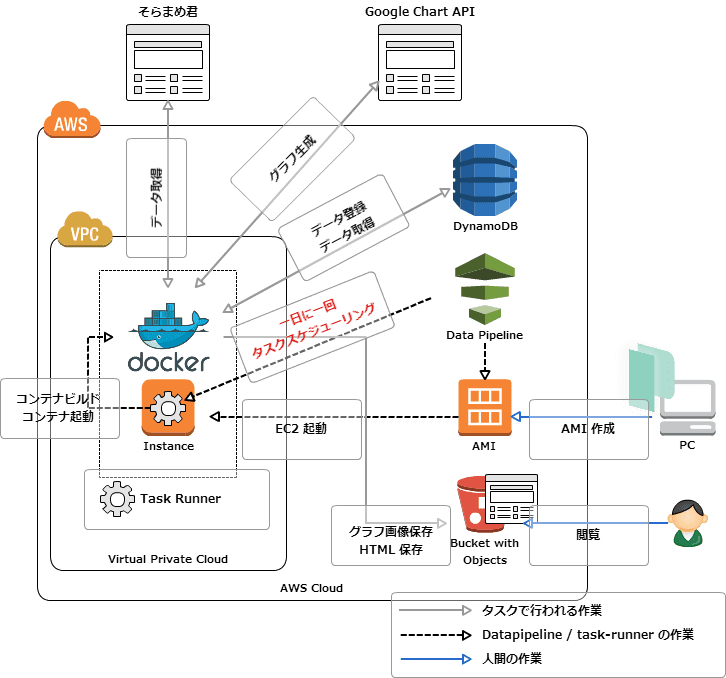
構成図
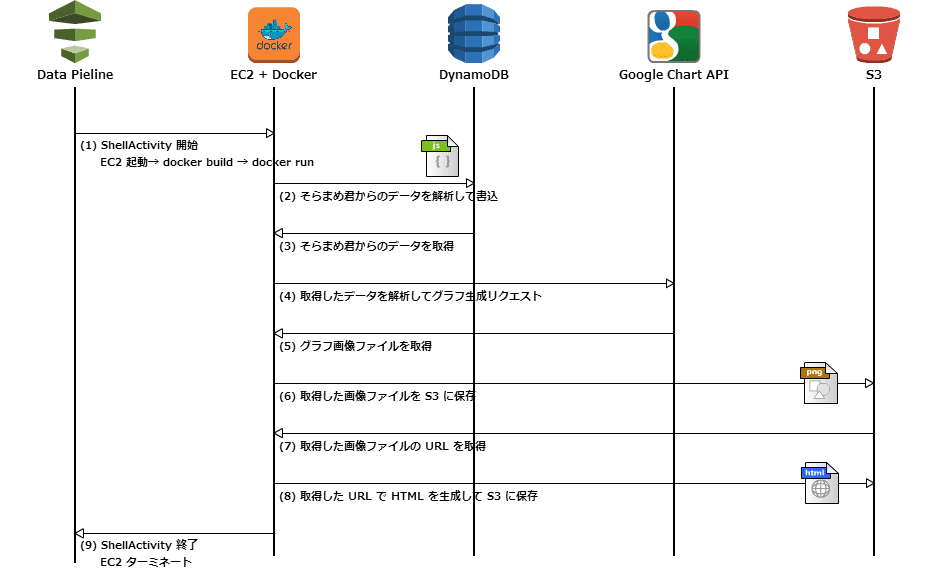
処理の流れ
ソースコードとか
- メインとなるソースコード
- Data Pipeline のパイプライン定義
{
"objects": [
{
"directoryPath": "#{myS3OutputLoc}/#{format(@scheduledStartTime, 'YYYY-MM-dd-HH-mm-ss')}",
"name": "S3OutputLocation",
"id": "S3OutputLocation",
"type": "S3DataNode"
},
{
"output": {
"ref": "S3OutputLocation"
},
"stage": "true",
"name": "ShellCommandActivityObj",
"id": "ShellCommandActivityObj",
"runsOn": {
"ref": "EC2ResourceObj"
},
"type": "ShellCommandActivity",
"command": "#{myShellCmd}"
},
{
"subnetId": "subnet-12345678",
"imageId": "ami-12345678",
"securityGroupIds": "sg-12345678",
"instanceType": "t1.micro",
"name": "EC2ResourceObj",
"keyPair": "xxxxxxxxxxxxxxxxxxxxxxx",
"id": "EC2ResourceObj",
"type": "Ec2Resource",
"terminateAfter": "15 Minutes"
},
{
"period": "1 Day",
"startDateTime": "2015-09-17T07:59:00",
"name": "RunOnce",
"id": "DefaultSchedule",
"type": "Schedule"
},
{
"failureAndRerunMode": "CASCADE",
"schedule": {
"ref": "DefaultSchedule"
},
"resourceRole": "DataPipelineDefaultResourceRole",
"role": "DataPipelineDefaultRole",
"scheduleType": "cron",
"name": "Default",
"id": "Default"
}
],
"parameters": [
{
"description": "S3 output folder",
"id": "myS3OutputLoc",
"type": "AWS::S3::ObjectKey"
},
{
"default": "s3://us-east-1.elasticmapreduce.samples/pig-apache-logs/data",
"description": "S3 input folder",
"id": "myS3InputLoc",
"type": "AWS::S3::ObjectKey"
},
{
"default": "grep -rc "GET" ${INPUT1_STAGING_DIR}/* > ${OUTPUT1_STAGING_DIR}/output.txt",
"description": "Shell command to run",
"id": "myShellCmd",
"type": "String"
}
],
"values": {
"myShellCmd": "mkdir /tmp/buildncd /tmp/buildnwget https://raw.githubusercontent.com/inokappa/oreno-pipeline/master/Dockerfilendocker build --no-cache=true -t soramame-runner .ndocker run --env 'AWS_REGION=ap-northeast-1' --env 'S3_BUCKET=your.example.com' soramame-runner > ${OUTPUT1_STAGING_DIR}/output.txt",
"myS3InputLoc": "s3://your-input-bucket/",
"myS3OutputLoc": "s3://your-output-bucket/"
}
}
- Data Pipeline で利用する Dockerfile
FROM ruby MAINTAINER inokappa RUN apt-get update RUN git clone https://github.com/inokappa/oreno-soramame-pipeline.git /app RUN chmod 755 /app/run.sh RUN mkdir -p /app/output/html RUN mkdir -p /app/output/png RUN gem install aws-sdk nokogiri googlecharts --no-ri --no-rdoc CMD /app/run.sh
Data Pipeline は
- 一日一回の処理(cron)として利用
- Shell Activity にて Docker コンテナを利用
- 標準出力を S3 に保存(S3 Output Location で定義した出力先に出力)
Docker コンテナ
- 処理を行うスクリプトをコンテナ化
- AMI 作るよりも楽、スクリプトのメンテナンスし易い(と思った)
- 毎回 build させる(最新のソースコードで処理させることが出来るしビルドの時間は 5 分程度なので全体の処理時間への影響は少ない)
最後に
感じたこと
- Data Pipeline の Shell Activity は Cron の代替になりうる(但し 15 分未満の間隔を定義することは出来ないので注意)
- ちょっとしたスクリプトとかも Docker コンテナ化しておくとよさ気
- DynamoDB の Scan や Query のフィルタがイマイチ理解出来ていない
改善案
- Ruby のソースコードが極めて雑でエラー処理等殆ど入っていないのでちょこちょこ直していきたい
- DynamoDB の検索結果が怪しい(抽出条件の指定方法が怪しい)ので見直す
- 出来るだけリアルタイム性を持たせるようにする
- 任意の条件で検索、グラフ描画出来るようにしたい
- グラフ上位地点名と地図上地点をリンクさせたい
DynamoDB と Datapipeline
- DynamoDB のパフォーマンス面等について引き続き調査
- Datapipeline のエラーハンドリング、リトライ処理について引き続き調査
- S3 のデータを Datapipeline 経由で DynamoDB にインポート(簡単そうで難しかった)をリトライ
元記事はこちら
「DynamoDB + Data Pipeline + S3 + Google Chart API を少しずつ使ってそらまめ君で提供されている大気中の汚染物質濃度速報データを可視化するサイトを作ってみた」
